Hi everyone, yes I’m back!
This is time we are going to setup a Big Data playground on Azure that can be really useful for any python/pyspark data scientist .
Typically what you can have out of the box on Azure for this task it’s Spark HDInsight cluster (i.e. Hadoop on Azure in Platform as a Service mode) connected to Azure Blob Storage (where the data is stored) running pyspark jupyter notebooks.

It’s a fully managed cluster that you can start in few clicks and gives you all the Big Data power you need to crunch billions of rows of data, this means that cluster nodes configuration, libraries, networking, etc.. everything is done automatically for you and you have just to think to solve your business problems without worry about IT tasks like “check if cluster is alive or check if cluster is ok, etc…” , Microsoft will do this for you.
Now one key ask that data scientist have is : “freedom!” , in other words they want to install/update new libraries , try new open source packages but at the same time they also don’t want to manage “a cluster” as an IT department .
In order to satisfy these two requirements we need some extra pieces in our playground and one key component is the Azure Linux Data Science Virtual Machine.

The Linux Data Science Virtual Machine it’s the Swiss knife for all data science needs, here you can have an idea of all the incredible tasks you can accomplish with this product .
In this case I’m really interested in these capabilities:
- It’s a VM so data scientists can add/update all the libraries they need
- Jupyter and Spark are already installed on it so data scientists can use it to play locally and experiment on small data before going “Chuck Norris mode” on HDInsight
But there is something missing here…., as a data scientist I would love to work in one unified environment accessing all my data and switch with a simple click from local to “cluster” mode without changing anything in my code or my configurations.
Uhmmm…. seems impossible, here some magic is needed !

Wait a minute , did you say “magic”? I think we have that kind of magic :-), it’s spark magic!
In fact we can use the local jupyter and spark environment by default and when we need the power of the cluster using spark magic when can , simply changing the kernel of the notebook, run the same code on the cluster!
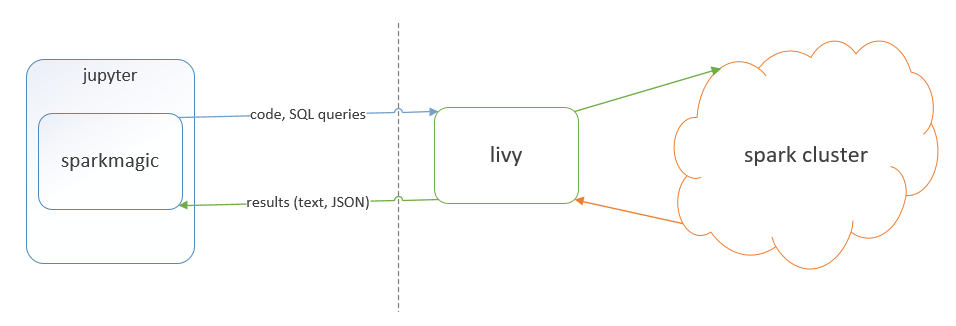 In order to complete the setup we need to do the following:
In order to complete the setup we need to do the following:
- Add to the Linux DS VM the possibility to connect , via local spark, to azure blob storage (adding libraries, conf files and settings)
- Add to the Linux DS VM spark magic (adding libraries, conf files and settings) to connect from local Jupyter notebook to the HDInsight cluster using Livy
Here the detailed instructions:
Step 1 to start using Azure blob from your Spark program (ensure you run these commands as root):
cd $SPARK_HOME/conf
cp spark-defaults.conf.template spark-defaults.conf
cat >> spark-defaults.conf <<EOF
spark.jars /dsvm/tools/spark/current/jars/azure-storage-4.4.0.jar,/dsvm/tools/spark/current/jars/hadoop-azure-2.7.3.jar
EOF
If you dont have a core-site.xml in $SPARK_HOME/conf directory run the following:
cat >> core-site.xml <<EOF
< ?xml version=”1.0″ encoding=”UTF-8″?>
< ?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
< configuration>
< property>
<name>fs.AbstractFileSystem.wasb.Impl</name>
<value>org.apache.hadoop.fs.azure.Wasb</value>
< /property>
< property>
<name>fs.azure.account.key.YOURSTORAGEACCOUNT.blob.core.windows.net</name>
<value>YOURSTORAGEACCOUNTKEY</value>
< /property>
< /configuration>
EOF
Else, just copy paste the two <property> sections above to your core-site.xml file. Replace the actual name of your Azure storage account and Storage account key.
Once you do these steps, you should be able to access the blob from your Spark program with the wasb://YourContainer@YOURSTORAGEACCOUNT.blob.core.windows.net/YourBlob URL in the read API.
Step 2 Enable local Juypiter notebook with remote spark execution on HDInsight (Assuming that default python is 3.5 like is coming from Linux DS VM ):
sudo /anaconda/envs/py35/bin/pip install sparkmagic
cd /anaconda/envs/py35/lib/python3.5/site-packages
sudo /anaconda/envs/py35/bin/jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel
sudo /anaconda/envs/py35/bin/jupyter-kernelspec install sparkmagic/kernels/sparkkernel
sudo /anaconda/envs/py35/bin/jupyter-kernelspec install sparkmagic/kernels/sparkrkernel
in your /home/{YourLinuxUsername}/ folder
- create a folder called .sparkmagic and create a file called config.json
- Write in the file the configuration values of HDInsight (livy endpoints and auth) as described here :
At this point going back to Jupyter should allow you run your notebook against the HDInsight cluster using PySpark3, Spark, SparkR kernels and you can switch from local Kernel to remote kernel execution with one click!

Of course some security features have to improved (passwords in clear text!), but the community is already working on this (see here support for base64 encoding) and ,of course , you can get the spark magic code from git, add the encryption support you need and bring back this to the community!
Have fun with Spark and Spark Magic!
UPDATE : here instructions on how to connect also to Azure Data Lake Store!
- Download this package and just extract these two libraries: azure-data-lake-store-sdk-2.0.11.jar , hadoop-azure-datalake-3.0.0-alpha2.jar
- Copy these libraries here “/home/{YourLinuxUsername}/Desktop/DSVM tools/spark/spark-2.0.2/jars/”
- Add their path to the list of library paths inside spark-defaults.conf as we have done before
- Go here and after you have created your AAD Application note down : Client ID, Client Secret and Tenant ID
- Add the following properties to your core-site.xml replacing the values with the ones you have obtained from the previous step:<property><name>dfs.adls.oauth2.access.token.provider.type</name><value>ClientCredential</value></property><property><name>dfs.adls.oauth2.refresh.url</name><value> https://login.microsoftonline.com/{YOUR TENANT ID}/oauth2/token</value></property><property><name>dfs.adls.oauth2.client.id</name><value>{YOUR CLIENT ID}</value></property>
<property><name>dfs.adls.oauth2.credential</name><value>{YOUR SECRET ID}</value></property>
<property><name>fs.adl.impl</name><value>org.apache.hadoop.fs.adl.AdlFileSystem</value></property>
<property><name>fs.AbstractFileSystem.adl.impl</name><value>org.apache.hadoop.fs.adl.Adl</value></property>